DuckDB + Dbt + great expectations = Awesome Data pipelines
I have been using spark for majority of data pipelines and while I like Spark for orchestrating my data transformations, sometimes it can be a complex beast with many so config options and settings. Spark is good for big data pipelines but its still an overkill for medium sized pipelines in 10–100gb range.
For in memory datasets, I have been mostly using pandas for doing transformations but it has its own cons as well
1. Pandas is a memory guzzler
2. Python knowledge is mandatory. My use case was more on analytic side where the transformations were in SQL.
With these in mind, I was looking for a more memory efficient solution and that is when I stumbled upon DuckDb.
DuckDB
In traditional OLTP systems such as PostgreSQL, MySQL or SQLite each row is processed sequentially. These are good for in point queries but they suck for analytical queries requiring aggregates, joins and merges.
DuckDB is an in-process SQL OLAP database management system. It contains a columnar vectorized query execution engine, where a large batch of values (a “vector”) are processed in one operation. This makes efficient use of the CPU cache and speed up response times for analytical query workloads.
Distributed version: Motherduck
Dbt
Dbt (data build tool) is a open-source analytics engineering tool that compiles and runs your analytics code against your data platform. At its core, it leverages the ELT (Extract, Load, Transform) approach, where data is extracted from various sources and loaded into a data warehouse or database first, and then transformations are applied on the raw data within the data warehouse itself.
Great Expectations
Great Expectations is an open-source Python library that provides a flexible and powerful framework for data quality checks and tests on databases, cloud storage solutions and file systems. One of the key features of Great Expectations is its ability to perform automated data quality checks. It allows data engineers to define a set of expectations for their data and automatically check the data against these expectations regularly.
Data pipeline
We can leverage the above three to build a data pipeline. I will be using a crypto dataset as a csv file and doing some transformations on top using DuckDb and Dbt and finally data quality tests using Great expectations

Setup:
You can setup in local or ec2 containers. Install the required packages using pip
pip install duckdb
pip install dbt-duckdbThis will install duckdb as well as dbt adapter for duck db. Post this run the below command to generate dbt folder structure
dbt init duckDbtThis will create a folder structure like below.

Now we need to install the great expectations package via dbt
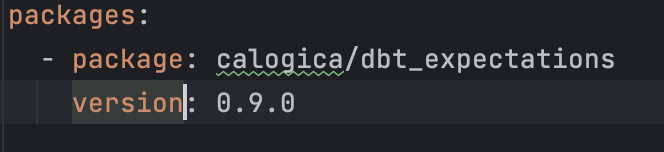
Create packages.yml file with below content and then run dbt deps
dbt deps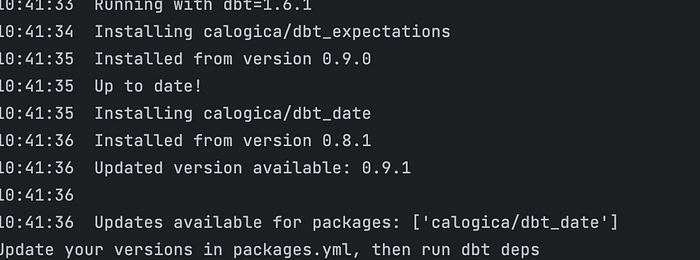
Once the package is installed, you can add test cases in schema.yml file like below. Detailed list of expectations (https://greatexpectations.io/expectations/)
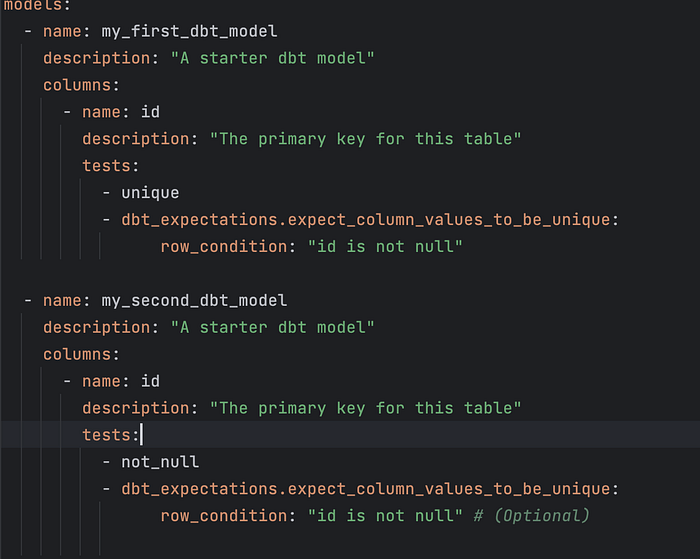
Post this just run dbt build to see the magic
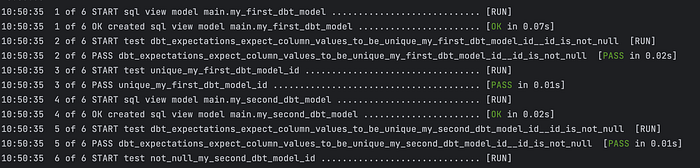
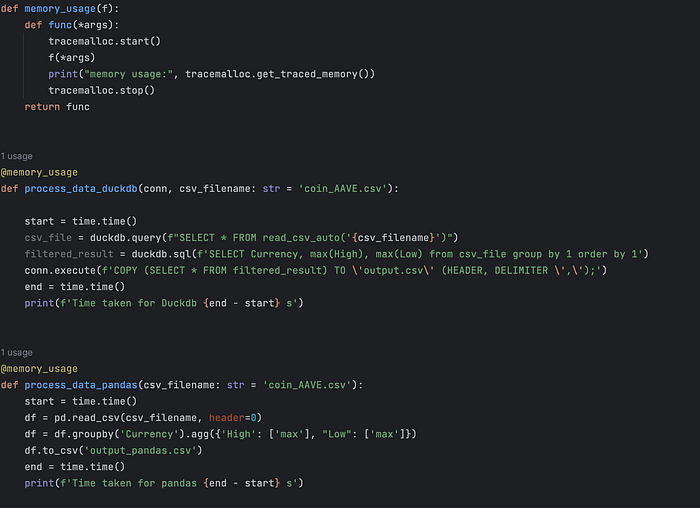
I did a memory/time taken comparison with pandas and below were the results
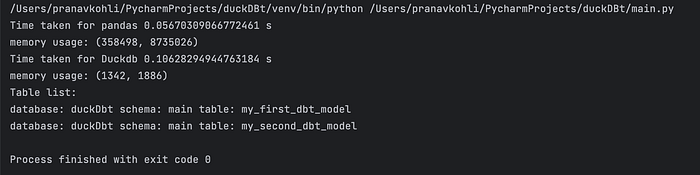
Pandas took half the time for doing the transformations but its memory went through the roof